{kind=link}
垃圾商品评论信息的识别研究*
引用本文
李霄, 丁晟春. 垃圾商品评论信息的识别研究*. 现代图书情报技术, 2013, 29(1): 63-68
Li Xiao, Ding Shengchun. Research on Review Spam Recognition. New Technology of Library and Information Service, 2013, 29(1): 63-68
Permissions
Li Xiao, Ding Shengchun. Research on Review Spam Recognition. New Technology of Library and Information Service, 2013, 29(1): 63-68
垃圾商品评论信息的识别研究*
摘要
从信息有用性的角度对垃圾商品评论信息进行分析, 选择数码领域的相机评论作为研究对象, 构建数据集, 从评论、评论者和被评论的商品三个方面选择11个特征, 使用支持向量机模型中4种常用的核函数进行垃圾商品评论的识别, 对识别效果较好的RBF核函数中的参数C和γ 进行优化, 使得商品评论中的垃圾评论识别的准确率提高到78.16%, 召回率提高到72.18%, 并选取4种不同特征组合进行对比, 证明评论、评论者和被评论的商品三大特征组合的效果最好, 最后通过与Logistic回归模型的对比, 验证SVM对垃圾评论的识别效果明显优于其他算法。
关键词:
SVM; 垃圾评论; 特征选择; 核函数; 商品评论信息
Research on Review Spam Recognition
Abstract
This paper analyses review spam from the perspective of the usefulness of information, selects digital camera reviews as the research object and builds the data set, then from the three aspects of review, reviewer and product chooses 11 features, uses 4 different kernel functions in SVM model to identify review spam of products, optimizes the parameters C and γ of RBF that has a better identification, which improves accuracy rate of the identification effect of review spam to 78.16% and recall rate to 72.18%. By comparing the selected 4 different combinations of features, the authors find the combination of review, reviewer and product is the best. Finally, it proves that SVM is significantly better than other algorithms compared to the Logistic Regression.
Keyword:
SVM; Review spam; Feature selection; Kernel function; Product review
1 引 言
随着Web的广泛使用以及用户主动参与的深入, 用户在购买和使用商品之后几乎都会通过网络发表对商品的评论, 这些商品评论信息包含了消费者对商品和服务的各种各样的观点。但是由于没有质量控制, 人们可以随意地在网络上发表自己的观点, 导致一些商品评论信息中含有一些无意义甚至不真实的信息。商品评论信息对商家及购物者都很重要, 因为它们不仅会影响潜在消费者的购买, 也会对商品制造者造成一定的影响。因此如何从海量的商品评论信息中识别出垃圾评论, 提取出有价值的信息资源, 成为意见挖掘领域一个比较热门的课题。目前大多数对垃圾评论的研究都集中在博客、论坛等方面, 但是对商品评论信息中的垃圾评论的研究非常少。本文以商品评论信息为研究对象, 首次从信息有用性角度分析商品评论信息, 探索出有效的评论特征与合适的机器
学习算法, 以更加高效准确地识别出商品评论信息中的垃圾评论。
周三多教授等在其《管理学原理》[1]一书中对有用信息的特征进行了详细的分析, 其特征主要包括:高质量的、及时的、完全的和相关的。对于消费者而言, 商品评论信息对其购买决策有相当大的影响, 因此商品评论是否有用成为一个有效的分类标准。本文从信息有用性角度对商品评论中的垃圾评论进行定义。具体来说, 商品评论中的垃圾评论有以下几种:.
(1)推销/诋毁评论:指为了推销或者诋毁某些商品或者品牌以获得利益, 自己或者请一些专业的造假者在网络上发表一些不符实际的、夸大的甚至是错误的评论。
(2)干扰信息:指发布广告、链接等与商品略微相关或者毫不相关甚至错误的信息, 来干扰用户或者误导自动观点挖掘系统。
(3)无意义信息:指发布一些内容不完整、空洞的、甚至毫无意义的评论信息, 或者是单纯宣泄自己的情绪的语句, 如:“ 好” 、“ 沙发” 、“ 喜欢” 等。
(4)系统评论:指由系统自身默认给出评论, 对用户没有任何作用。
基于以上对于垃圾商品评论信息的分类, 本文使用SVM算法作为垃圾商品评论信息的识别方法, 选择数码领域的相机评论信息作为研究对象, 从评论内容、评论者、被评论商品三方面来选择多个特征, 设计特征选择对比实验, 以验证本文所选特征的有效性与关键性, 最后对比SVM与Logistic回归模型的识别效果, 以验证SVM模型的有效性与优点。
2 相关工作
国内外学者对垃圾网页和垃圾邮件的研究非常广泛, 对其处理方法也很成熟, 但是对垃圾评论的识别研究相对较少。近年来, 研究者逐渐开始关注博客、电子商务等领域的垃圾评论。Jindal等[2, 3]在2008年首先定义三种类型的垃圾评论, 即不真实的评论(类型1)、无关评论(类型2)和非评论(类型3), 之后人工标注部分垃圾评论, 以评论、评论者和被评论的商品三个方面的24个特征作为基本特征, 使用Logistic回归构建机器学习模型, 识别类型2和类型3的垃圾评论, 使用Shingle算法识别重复的评论, 并使用识别出的重复评论作为训练集构建机器学习的模型来识别类型1的垃圾评论。他们发现使用重复评论作为训练集会遗漏一部分非重复的垃圾评论, 于是在2010年他们分析了用户的打分模式[4, 5, 6], 并通过挖掘用户的行为, 发现反常的评论模式来分析用户是垃圾评论发表者的可能性。Mukherjee等[7]在2010年使用三个步骤来检测群体垃圾评论, 首先使用Frequent Pattern Mining找出候选的群体, 之后计算垃圾信息的指示值, 最后使用支持向量机(Support Vector Machines, SVM)算法进行排名, 从而检测出群体垃圾评论。Wu等[8]利用正向的Singletons(评论发表者发表的唯一的一条评论)在一个产品的所有评论中所占的比例和这些Singletons 时间聚集程度来分析评论发表者的可疑行为。何海江[9]在2009年提出了一种用来衡量评论与文章之间的语义相关程度的向量空间模型cVSM作为评论的特征, 采用支持向量机分类算法自动识别垃圾评论, 能显著地提高垃圾评论的识别能力。之后何海江等[10]在评论识别时, 采用基于Logistic回归的分类器来区分合法评论和垃圾评论, 并与支持向量机SVM的性能进行对比。Bhattarai等[11]在2009年研究了博客垃圾评论的特征, 并利用Co-training思想从已给的数据中主动学习的方法来解决对识别不好或是无法识别的评论的问题。
目前, 垃圾评论的识别方法大都建立在文本分类的思想上, 将其识别过程视为垃圾评论和非垃圾评论的二分类。其具体过程是:首先构建标准数据集, 选择数据集中部分数据作为训练样本, 然后针对要分类的对象, 找出特征, 最后运用Logistic回归、贝叶斯、条件随机场、SVM等算法进行分类。通过对之前学者研究的学习, 笔者最终选择SVM算法来完成对垃圾商品评论信息的识别研究。
3 方 法
3.1 支持向量机模型
SVM是由贝尔实验室的Vapnik等人于20世纪90年代在统计学习理论的VC 维和结构风险最小化基础上提出的, 它借助于有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求平衡, 以得到较好的推广能力[12, 13]。
概括来说, SVM首先通过核函数将输入空间变换到一个高维特征空间, 然后在这个空间求最优分类面。SVM模型中的核函数有效解决了维数灾难, 比较常用的核函数包括线性核函数、RBF核函数、q次多项式核函数和Sigmoid核函数。SVM基本上不涉及概率及大数定律等, 因此不同于现有的统计方法。它通过提高数据的维度把非线性分类问题转换成线性分类问题, 较好地解决了传统算法中训练集误差最小而测试集误差较大的问题, 算法的效率和精度都比较高。SVM在函数表达能力、推广能力和学习效率上都要优于传统方法, 在解决有限样本、非线性及高位模式识别问题中取得了较好的效果。此外, 支持向量机是一个凸二次优化问题, 能够保证找到的极值解就是全局最优解。这些特点使支持向量机成为一种优秀的基于数据的机器学习算法。近几年来, SVM方法已经凭借其优势在文本分类、手写识别、信号处理、基因图谱识别和图像识别等方面得到了成功的应用。
3.2 特征选择
在SVM模型中, 特征的选取会直接影响到模型的识别效果。本文从评论、评论者、被评论的商品三个方面进行垃圾商品评论识别特征的选择, 特征如下:.
(1)以被评论商品为中心的特征。商品名称(F1):一条评论如果提到了产品名称, 那么这条评论极有可能不是垃圾评论。商品的属性(F2):一条评论如果没有提到与该产品的属性相关的信息, 那么这条评论极有可能是垃圾评论。
(2)以评论者为中心的特征。评论者名称(F3):一般情况下, 认为非匿名用户发表的评论比匿名用户发表的评论更具可信性。
(3)以评论为中心的特征。评论的长度(F4):通过统计实验发现, 一般较短的评论是垃圾评论的可能性很大, 这个评论的长度F4的阈值设为10个字符是比较适中的, 即长度小于10个字符的评论为垃圾评论的可能性更大。评论中的正面评价词(F5)、负面评价词(F6)、正面情感词(F7)和负面情感词(F8):一些垃圾评论制造者可能会使用这些评价词或情感词来过分赞扬或者批评产品或者制造商等。因此, 如果一条评论对某一产品过分赞扬或者贬低, 这条评论中可能会含有多个评价词或者情感词, 该评论为垃圾评论的可能性就比较大。本文使用HowNet情感词典[14]作为种子词典, 并加入一些网络新词, 去掉一些不常用的词, 构建评价词和情感词词典。评论中同类产品的不同品牌(F9):这个特征更有助于识别某些针对品牌的推销或诋毁的垃圾评论。通过阅读网站上商品的评论后, 笔者发现, 如果某些评论刻意诋毁或赞扬某些品牌, 这时会出现其他品牌, 该评论极有可能为垃圾评论。评论中的字母(F10)和数字及字符(F11):这些特征对识别非评论非常有用, 字母意味着不良的或者无关的评论, 数字及字符的过度使用意味着可能是虚假的或者无意义的评论。
每条评论使用以上特征来表示, 构成特征向量。特征的计算方法如下所示:.
F1=n, (n=0, 1) (0:评论中不存在该产品的名称; 1:评论中存在该产品的名称).
F2=n, (n=0, 1, 2… ) (n:评论中存在该产品的属性的数量).
F3=n, (n=0, 1) (0:匿名或半匿名评论者; 1:存在评论者名称).
F4=n, (n=0, 1)(0:评论长度小于等于10个字符; 1:评论长度大于10个字符).
F5(F6)=评论中正(负)面评论词的数量评论中所有评论词的数量.
F7(F8)=评论中出现的正(负)面情感词的次数评论中出现的所有情感词的次数.
F9=评论中提到该产品品牌的次数评论中提到的所有品牌的次数.
F10=一条评论中字母的总数这条评论的长度.
F11=一条评论中数字及字符的总数这条评论的长度.
每条评论使用以上特征来表示, 构成特征向量。
3.3 实验方案
可以看出, 其基本流程如下:随机选取部分评论信息作为训练语料, 剩余的评论作为测试语料; 调用LibSVM工具, 使用4种不同的核函数对训练语料进行训练, 生成模型文件; 使用模型文件对测试语料进行处理, 得到实验结果; 分析实验结果, 选择识别效果较好的核函数, 使用LibSVM工具对该核函数中的参数进行优化, 将得到优化后的参数输入到模型中, 对测试语料进行处理, 得到最终结果。在模型对比实验中, Logistic回归模型的实验流程与SVM模型的相似。
本文选取相机评论信息作为研究对象, 采用LibSVM工具[15]和Weka[16]软件中的Logistic回归模型对实验语料进行训练与预测, 获得评论信息分类的结果。在选择研究对象后, 首先使用SVM算法进行实验, SVM分类实验的基本流程如图1所示:
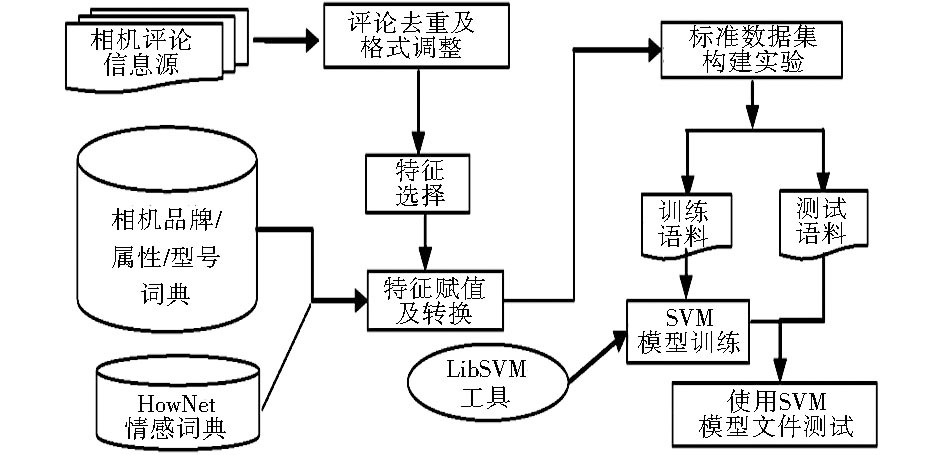 | 图1 SVM分类实验流程图 |
可以看出, 其基本流程如下:随机选取部分评论信息作为训练语料, 剩余的评论作为测试语料; 调用LibSVM工具, 使用4种不同的核函数对训练语料进行训练, 生成模型文件; 使用模型文件对测试语料进行处理, 得到实验结果; 分析实验结果, 选择识别效果较好的核函数, 使用LibSVM工具对该核函数中的参数进行优化, 将得到优化后的参数输入到模型中, 对测试语料进行处理, 得到最终结果。在模型对比实验中, Logistic回归模型的实验流程与SVM模型的相似。
本文采用文本分类器中最常用的评测指标:准确率(Precision)、召回率(Recall)和F-measure作为垃圾评论识别的评判标准。
4 实验与结果分析
4.1 数据集介绍
(注:2012年6月2日数据。).
数据集会直接影响实验的准确性与科学性。目前在商品评论领域内, 并没有专门提供的有关垃圾商品评论的中文数据集。Alexa排名是目前常引用的用来评价某网站访问量的一个指标。为使实验数据集具有代表性和真实可靠性, 本文选择Alexa排名前1 000位的主营业务包含相机的第三方点评、电子商务平台等类型网站来获取相机评论。这些网站的日均页面浏览量比较高, 即这些网站的用户比较多, 他们可能会发表很多有关相机的评论, 这些评论也会被多人阅读, 对其他人产生一定的影响, 因此这些网站上的相机评论具有一定的代表性。具体的网站排名与日均页面浏览量如表1所示:
| 表1 调查网站Alexa排名及其日均页面浏览量 |
从这些网站上获取相机评论信息, 对其进行预处理后, 得到15 000条评论信息。选择15名实验者, 分为三组, 对预处理后的评论进行垃圾评论与非垃圾评论的人工标注, 选择三组中结果相同的评论作为实验的数据集。最终的数据集有10 209条相机评论信息, 其中垃圾评论5 486条, 非垃圾评论4 723条。
4.2 实验结果分析
.
即:在11个特征中只要有2个特征比较明显, 模型就能有效地将评论分类。这说明本实验特征选择的有效性, 但是还需要进一步细化。从表3可以看出, 调整参数后的SVM模型的召回率大大提升, 被正确识别为垃圾评论的数量由673增加到832, F-measure由66.56%上升到75.05%, 参数优化后的识别能力显著提高。
使用SVM模型对4种特征组合进行对比, 通过表4中F-measure可以看出, 组合评论、评论者、被评论的商品三大特征(组合4)对于垃圾商品评论的识别效果最好。实验结果表明:仅使用评论特征来识别垃圾的商品评论不够。一条评论是否为垃圾评论不仅与评论内容本身有关, 也与评论者、被评论的商品有关。被评论的商品的特征可以辅助模型识别与当前商品无关的评论, 评论者特征可以辅助模型识别推销或诋毁类的评论信息, 因此将三大类特征组合, 可以有效地提高垃圾商品评论的识别效果, 同时也说明这三大特征对于垃圾商品评论的识别来说是关键的特征。
对SVM模型和Logistic回归模型分别进行十折交叉验证, 最终对同一测试集测试的结果可以看出:SVM模型的F-measure为75.05%, 明显高于Logistic回归模型。SVM模型中的最终决策函数只有少数的支持向量所确定, 也就是说训练样本中只有关键评论样本作为支持向量, “ 剔除” 大量冗余样本, 降低了计算的复杂度, 最大化了分类的边际, 从而提高了垃圾评论识别的准确率与召回率。而Logistic回归采用的是最大似然估计, 它的优点是建立在大样本的基础上。与Logistic回归模型相比, SVM模型在较少的数据集上仍能得到比较好的训练结果。另外, 本实验所选取的特征转化为数据后, 数据是相对稀疏的, 而SVM算法对稀疏矩阵的计算效果也优于Logistic回归模型。
(1)SVM算法的4种核函数模型对比实验.
该实验使用4种核函数SVM模型对同样的数据集进行垃圾评论的识别, 其识别结果如表2所示:
| 表2 核函数对比实验结果 |
可以看出, 线性核函数与RBF核函数对垃圾评论信息识别的准确率明显好于另外两种核函数, 但是线性核函数的召回率比较低, 而RBF核函数的召回率也略微高于其他核函数。RBF核函数在本实验中对垃圾评论的识别效果比较好是因为选择了11个特征, 特征维度相对较高, 而RBF核函数将其有效地映射到高维的特征空间, 这样数据集中的垃圾评论和非垃圾评论肯定是线性可分的, 而且效果会相对较好, 垃圾评论被正确识别出的数量也比较高。
(2)RBF核函数参数优化实验.
本文针对识别效果最好的RBF核函数进行参数优化, 以获得对垃圾评论更高的识别精度。实验结果如表3所示。
参数优化过程主要是利用软件包提供的交互检验功能进行寻优, 优化的参数包括控制经验风险和VC维平衡的参数C和控制支持向量机对输入量变化的敏感程度的γ , RBF核函数优化后的参数C = 2 048.0; γ =0.5。参数C的默认值为1.0, 调整后的参数C取2 048.0这个较大的数值降低分类的误差, 从而实现了对训练样本较好的拟合。γ 的默认值为1/k(k为特征数), 本文选择11个特征, 即γ 的值为1/11, 调整后, SVM模型对输入量变化的敏感度由1/11变为0.5,
| 表3 RBF核函数参数优化实验结果 |
即:在11个特征中只要有2个特征比较明显, 模型就能有效地将评论分类。这说明本实验特征选择的有效性, 但是还需要进一步细化。从表3可以看出, 调整参数后的SVM模型的召回率大大提升, 被正确识别为垃圾评论的数量由673增加到832, F-measure由66.56%上升到75.05%, 参数优化后的识别能力显著提高。
(3)特征选择对比实验.
该实验设置了4种特征组合:评论特征、评论者特征+ 评论特征、产品特征+ 评论特征、评论者特征+ 产品特征+ 评论特征, 之后使用SVM模型进行垃圾商品评论的识别。实验结果如表4所示:
| 表4 特征组合对比实验结果 |
使用SVM模型对4种特征组合进行对比, 通过表4中F-measure可以看出, 组合评论、评论者、被评论的商品三大特征(组合4)对于垃圾商品评论的识别效果最好。实验结果表明:仅使用评论特征来识别垃圾的商品评论不够。一条评论是否为垃圾评论不仅与评论内容本身有关, 也与评论者、被评论的商品有关。被评论的商品的特征可以辅助模型识别与当前商品无关的评论, 评论者特征可以辅助模型识别推销或诋毁类的评论信息, 因此将三大类特征组合, 可以有效地提高垃圾商品评论的识别效果, 同时也说明这三大特征对于垃圾商品评论的识别来说是关键的特征。
(4)不同模型的对比实验.
使用RBF核函数的SVM模型和Weka软件自带的Logistic回归模型对相同的数据集进行垃圾商品评论的识别, 对比两种模型的识别效果。实验结果如表5所示:
| 表5 不同模型的对比实验结果 |
对SVM模型和Logistic回归模型分别进行十折交叉验证, 最终对同一测试集测试的结果可以看出:SVM模型的F-measure为75.05%, 明显高于Logistic回归模型。SVM模型中的最终决策函数只有少数的支持向量所确定, 也就是说训练样本中只有关键评论样本作为支持向量, “ 剔除” 大量冗余样本, 降低了计算的复杂度, 最大化了分类的边际, 从而提高了垃圾评论识别的准确率与召回率。而Logistic回归采用的是最大似然估计, 它的优点是建立在大样本的基础上。与Logistic回归模型相比, SVM模型在较少的数据集上仍能得到比较好的训练结果。另外, 本实验所选取的特征转化为数据后, 数据是相对稀疏的, 而SVM算法对稀疏矩阵的计算效果也优于Logistic回归模型。
5 结 语
本文以相机评论信息作为研究对象, 从信息的有用性角度对垃圾商品评论的特征进行概述, 并基于文本分类的思想, 验证SVM算法中4种不同核函数对垃圾评论的识别效果, 选择效果较好的核函数进行参数优化, 进一步提高垃圾评论的识别效果, 之后对比不同特征组合的SVM模型对垃圾商品评论的识别效果, 并将SVM模型与Logistic回归模型进行对比。实验结果表明, RBF核函数的识别效果明显好于其他三种核函数, 而且参数优化后, 垃圾商品评论的识别效果也有明显的提高, 被评论的商品、评论者和评论三大特征是垃圾评论识别的关键特征, SVM模型相对于其他类型的算法在垃圾商品评论的识别方面有明显的优势。
在今后的工作中, 需要解决的问题是对垃圾评论进一步细化, 并完善实验所选择的特征, 使用SVM模型对垃圾评论进行多类分类。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|